By Ami Levin, SQL Server MVP
How many times have you made a small change to a certain aspect of the database (schema, code, indexing etc.) and prayed that it wouldn’t have any unexpected side effects on your workload? In a recent article, ‘The Hidden Menace of CREATE INDEX’, I discussed one potential aspect of this issue, the unexpected and hard-to-predict impact of adding indexes. In this article, I will discuss the ‘Database Operations’ feature of Qure Optimizer . This sometimes-overlooked feature can be a great help in predicting the potential scope-of-effect for any recommended change you are about to apply to the database. This will help you avoid the potentially devastating ‘butterfly effect’, where even a small (but not carefully considered) change can have unfortunate consequences.
The key to this is to understand the correct SQL object dependency hierarchy. Whenever you are about to make a change to an object, you want to know exactly which other objects or queries might be affected by it. Up till SQL 2008, SQL server offered a few options to track dependency: the sysdepends system table, sp_depends system procedure and (in SQL 2005) the sql_dependencies view. These objects allowed us to explore the dependency hierarchy as stored internally by SQL Server. SQL Server management studio dependency views used these objects to display the dependency hierarchy visually. However, these records were far from accurate. SQL Server recorded only some of the dependencies but failed to record many others. For example, because of deferred named resolution and since the references were recorded by object ID, obviously SQL Server could not resolve an ID for an object that does not yet exist. Additionally, logical issues prevent SQL Server from correctly recording other dependencies. Among others, the following dependencies were not recorded:
- Objects created using deferred name resolution. For example, you can create procedure X which accesses table Y before the table even exists. In that case, the dependency is not recorded.
- Objects referenced from other databases on the same instance.
- Objects referenced from other instances.
- Objects referenced using dynamic SQL code.
SQL 2008 introduced a new dependency tracking system that uses object names instead of IDs (the first natural key in SQL Server system tables, as far as I know). The data is exposed via a system view (sql_expression_dependencies) and two system functions (dm_sql_referenced_entities and dm_sql_referencing_entities). This new system overcomes the major obstacle of tracking object dependencies of objects using deferred name resolution. This new system also overcomes the cross-database and cross-instance limitations in most cases. If you look at the syntax for using these new views and functions, you will see that it requires some effort in filtering, formatting and decrypting the information returned. It also does not natively support tracking dependencies across multi-level hierarchies.
If you are using SQL 2005, or even if you are using SQL 2008, and you are about to apply some of Qure Optimizer’s recommendations, I want to draw your attention to the native dependency tracking offered by Qure Optimizer. Qure Optimizer’s tracking is based on syntax parsing and schema analysis of the objects. Therefore, you should be aware that objects that were not used during the captured workload will not be parsed and their dependencies won’t be tracked. In addition, you should be aware that the Qure Optimizer parser has some limitations (for example it doesn’t parse Xqueries) so before you trust the dependency tracking, be sure to consult the limitations and known issues section on DBSophic’s web site. If these limits are not an issue, you can take advantage of Qure Optimizer’s dependency tracking, also known as the ‘Database Operations’ feature.
You can view the database operations from the Batches and the Objects windows. For each batch or group of selected batches, the bottom pane provides a dedicated tab that lists the operations that this batch or batches perform in the database. The available operations are:
- Executes <stored procedure>
- Calls <function1>, <function2>… n
- Selects from <table1>, <table2>… n
- Inserts to <table1>, <table2>… n
- Updates <table1>, <table2>… n
- Deletes from <table1>, <table2>… n
Below is a screenshot of the database operations pane with six selected batches.
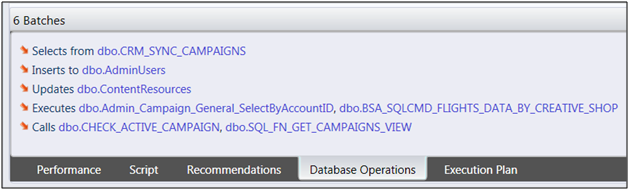
Screenshot 1 - Database Operations of Batches
Each one of the blue object names is a hyperlink that will take you to the Objects page and select that object for you so you can easily continue to drill and climb up and down the dependency hierarchy with a click of a mouse. For example, clicking the top object link, CRM_SYNC_CAMPAIGNS, will take you to the batches page and provide you with the following information:
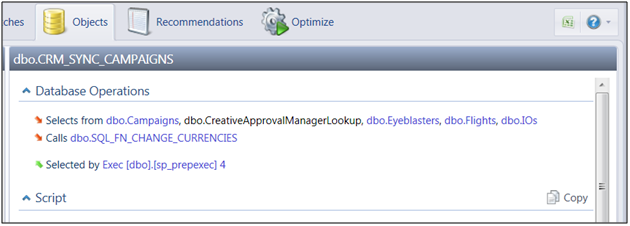
Screenshot 2 - Database Operations of a View
Now you can see that this object is actually a view, and you can uncover all objects which are accessed by that view. The downward red arrows indicate objects which this view accesses while the upward green arrows indicate objects that access this view. In our case it’s a dynamic batch. If I want to drill down further and see the dependencies of the Campaigns table, just click the link and navigate to that object:
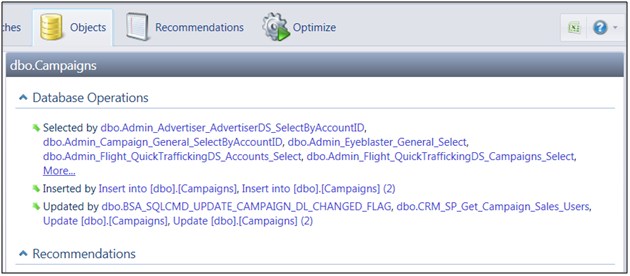
Screenshot 3 - Database Operations for a Table
Here you can now see all the batches that access the campaigns table and realize the full scope of effect that making any change to it might have. Of course, you can use the batch links to navigate back to the batches page and see what the actual benchmark results were for that batch.
Overall, the database operations feature of Qure Optimizer allows you to easily and quickly navigate down and up the dependency tree of each batch or object and to easily plan your changes taking into account every potential effect on your entire workload.
This is workload tuning at its best…