By Ami Levin, SQL Server MVP
In Part I of this series on physical join operators we looked at Nested Loops. We now turn our attention to the Merge operator.
For this article series I am using an analogy of two sets of standard playing cards. One set with a blue back and another with a red back that need to be 'joined' together according to various join conditions. The two sets of cards simply represent the rows from the two joined tables, the red input and the blue input - "Now Neo - which input do you choose"?

A merge operator can be used only when both sets of rows are pre-sorted according to the join expression(s). For example, a Product table index andOrder Detail table index both sorted by Product ID (recall Execution Plan 3 from the Nested Loops articles). The algorithm is extremely simple, elegant, and efficient:
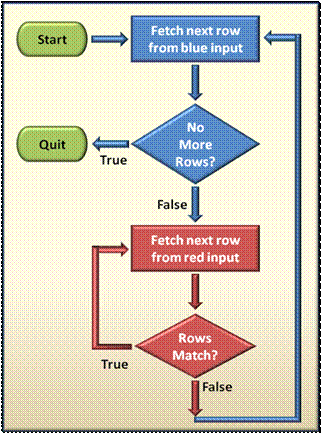
Flowchart 2 - Merge
Since the rows are sorted according to the join expression(s), we can immediately begin the matching process. Simply get the first row from the blue input and the first row from the red input. If they match, output them and continue to the next row from the red input. If not, fetch the next row from the blue input and repeat the processes until all rows from the blue input have been processed. If we were to join our cards this way, we would first lay both sets on the table, sorted according to the join condition, let's say suit and rank. We will probably spread them one row below the other and simply start picking the cards, moving from left to right on both rows and matching as we progress. Of course, we could decide to sort them just for this purpose even if they weren't sorted to begin with.
Merge is a highly efficient operator
The merge join is probably the most efficient of all three operators. It combines the advantage of hash match where the actual data needs to be accessed only once with the advantages of nested loops - low CPU consumption and enabling of fast output of matched rows for further query processing. Moreover, it tops them both by eliminating the potential for a-sequential page flushes. Since the days of SQL Server 6.5, I have witnessed how the query optimizer tends to favor merge joins more and more with every new release. In SQL 2000, we would see merge joins almost exclusively for joins that had the appropriately pre-sorted indexes, and for queries that included an ORDER BY clause that required the sort. In SQL 2008 the optimizer cleverly realizes that the advantages of this join operator justify pre-sorting of one or both inputs just for the sake of using merge in many more cases than previous versions did.
Let's check out a few examples that use the Merge join operator.
Merge join with Clustered Indexes
The most obvious example, as can be seen in Query 5, is a join that uses the keys of the clustered indexes of both tables. Since a clustered index is actually the table itself, sorted in the order of the clustered index key(s), the clustered index covers all queries and can be used to retrieve any (non BLOB) column in the table you specify in your SELECT clause. Even the SELECT * in the query below will not require any additional table lookups. But remember that there is still a penalty to pay for retrieving all columns unnecessarily as both tables will need to be fully loaded into memory and sent over the network.

Query 5
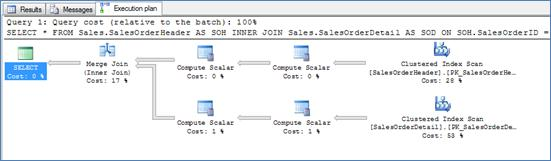
Execution Plan 5
* Challenge #2: There are no expression computations in this query. Try to guess what the ‘compute scalar’ operators in Execution Plan 5 above are for…
Hint: The answer is at the columns node of these tables in SSMS object explorer.
Merge join with Non Clustered Indexes
Merge will be very efficient when one or both tables have a non clustered index that sorts the join column. This is twice as true if the index covers the query, as in Query 6.

Query 6
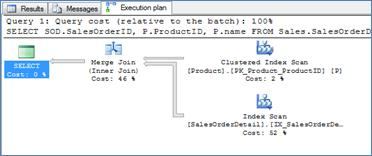
Execution Plan 6
* Exercise: In the demo code I’ve added two more examples (Queries 6b and 6c) where a small change to the query changes the physical operator chosen by the SQL Server optimizer. Try to play around with the parameters and see how the optimizer changes its decisions.
ORDER BY clause may coax a Merge join
As I mentioned earlier, in many cases you will see that the optimizer decides to sort one or both inputs just to use the merge operator. This will usually happen when the inputs are not very large and the alternatives are worse. This decision becomes even easier if the optimizer sees that performing a sort provides an additional benefit, allowing the optimizer to 'kill two birds with one stone' (see disclaimer below) For example, the pre sorting may help facilitate the highly efficient stream aggregate for GROUP BY or DISTINCT clauses , UNION operators, analytical rankings or for delivering the result set in the order of the ORDER BY clause, as is the case in Query 7 .

Query 7
DISCLAIMER: No birds (nor any other animals) were harmed for the making of this script. As a matter of fact, three of my cats actually assisted the writing of this article. One is purring in my lap as I’m writing these lines…
In Part III we will conclude this series with a look at the Hash operator.
If you are interested to dive deeper and learn more on joins and their implementation in SQL Server, I highly recommend Craig Freedman's SQL Server Blog on MSDN. Craig has published a series of excellent, in depth articles regarding many more aspects and types of joins.